kafka 에서는 auto commit 이라는 기능을 지원한다.
auto commit 이란 consumer 에서 offset 을 자동으로 커밋하는 기능을 뜻한다.
그렇다면 offset 은 무엇일까? auto commit 이 어떤 기능인지 이해를 하려면 offset 을 먼저 알아야 한다.
Offset 이란?
offset 은 kafka 에서 데이터를 관리하기 위한 기능으로 카프카에 메시지를 추가할 때 토픽의 특정 파티션에 추가되게된다.
각 메시지는 토픽에 순차적으로 저장되며 그 순서에 따라 가지는 번호를 offset 이라고 한다.
* 메시지가 offset 을 가지는것은 아니다.
Auto Commit
다시 auto commit 으로 돌아와서 얘기를 해보고자 한다.
카프카에 메시지에 추가될 때 파티션의 메시지별로 고유한 offset 이 부여되게 된다는것까지 알아보았다.
그러면 이제 Consumer 입장을 생각해보도록 하자.
Consumer 는 메시지를 가져와서 처리하는 역할을 가진다.
데이터를 처리하기 위해서는 "어디까지" 처리했는지와 "어디서부터" 처리를 해야하는지를 알아야한다.
Consumer 는 이것을 알기위하여 offset 을 활용한다.
예를들어 0번 offset 부터 5개의 데이터를 줘! 라고 요청할 수 있다. 그리고 모두 처리한 후 5번까지 처리했어 라고 알리게된다.
이때 어디까지 처리했는지 알리는 작업을 commit 이라고 하며, 이를 자동으로 하는것을 auto commit 기능이라고 한다.
auto commit 은 2가지 옵션에 영향을 받는다.
- auto.commit.enable : true 일때 동작한다.
- auto.commit.interval.ms : offset 이 저장되는 주기를 뜻하며, 기본값은 5초이다.
Interval.ms 만 지나면 컨슈머는 자동으로 오프셋정보를 커밋할까?
처음 구독을 시작하여 consume 을 시작하면 아래와같은 정보를 가지고있다.

그렇다면 아래와 같이 데이터를 가져온 후 무한정 대기를 하게되면 어떤일이 발생할까?
Interval.ms 를 500ms 로 세팅했으니 바로 오프셋을 커밋할까?
테스트를 진행해보자
object KafkaConsumerFactory {
private val props = Properties().apply {
put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
put(ConsumerConfig.GROUP_ID_CONFIG, "demo-group")
put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer::class.java.name)
put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer::class.java.name)
put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true")
put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "500")
}
fun create(): KafkaConsumer<String, String> {
return KafkaConsumer<String, String>(props)
}
}
fun main() {
val consumer = KafkaConsumerFactory.create()
consumer.subscribe(listOf("test-topic"))
consumer.use { consumer ->
while (true) {
val records = consumer.poll(Duration.ofMillis(500))
for (record in records) {
println(record)
}
Thread.sleep(Long.MAX_VALUE)
}
}
}
데이터를 정상적으로 가지고왔고 print 까지 했다. 하지만 아무리 기다려도 아래와같이 offset 정보가 업데이트 되지않는것을 확인할 수 있다.
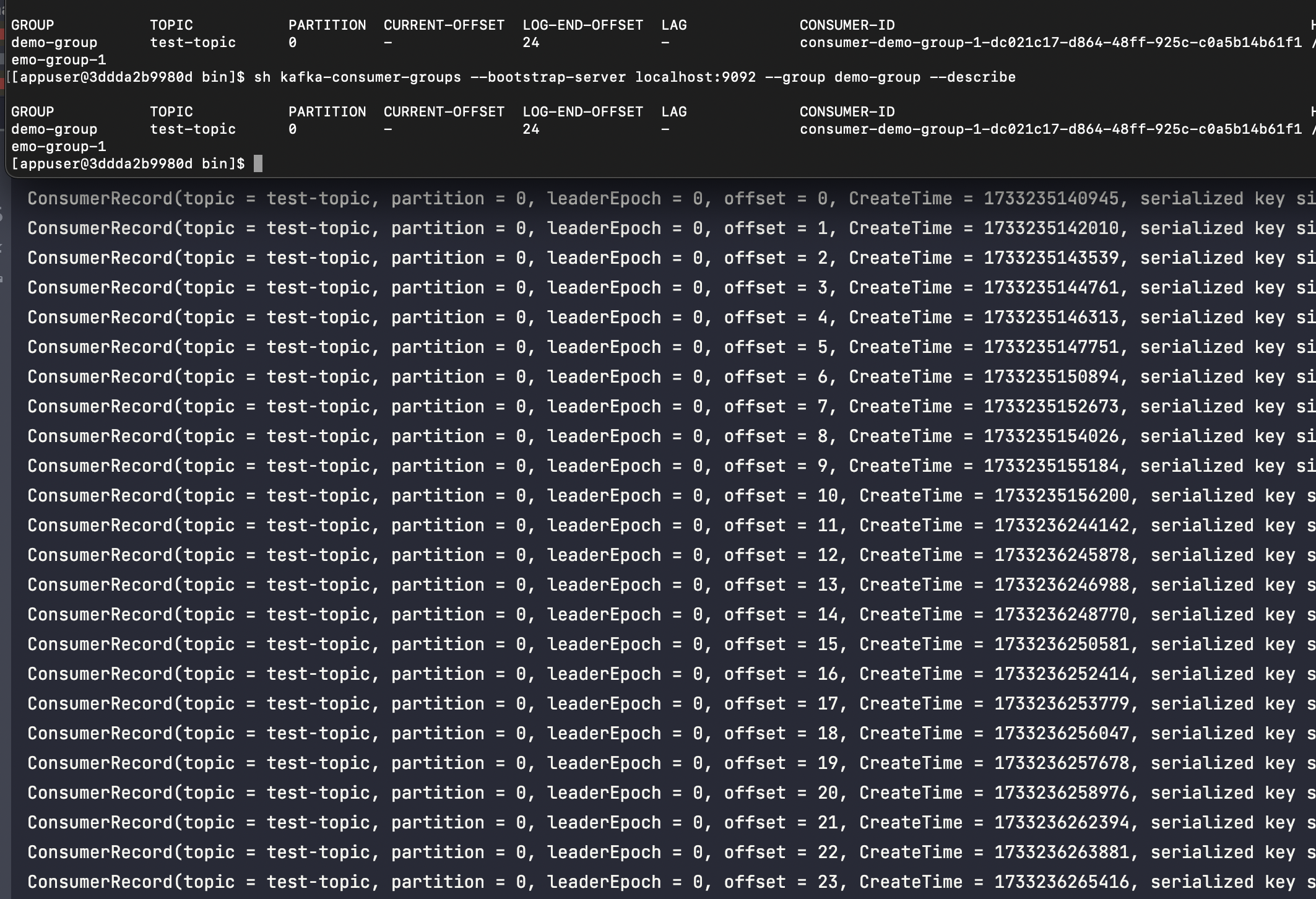
그렇다면 아래와같이 코드를 조금 변경해보고 다시 실행해보도록 하자.
fun main() {
val consumer = KafkaConsumerFactory.create()
consumer.subscribe(listOf("test-topic"))
consumer.use { consumer ->
while (true) {
val records = consumer.poll(Duration.ofMillis(500))
process(records)
}
}
}
fun process(records: ConsumerRecords<String, String>?) {
Thread {
if (records != null) {
for (record in records) {
println(record)
}
}
sleep(Long.MAX_VALUE)
}.start()
}
이번에는 print 를 하고 오프셋정보를 commit 한것을 확인할 수 있다.
눈치가 빠른 사람이라면 약간의 차이이지만 무엇이 차이인지 알 수 있을것이다. 바로 poll() 메소드를 호출했는가? 이다.
이전코드에서는 poll 작업을 수행한 후 Thread.sleep 을 수행하기때문에 poll 메소드 호출이 안되지만 수정한 코드에서는 새로운 스레드를 생성한 후 해당 스레드에게 작업을 위임한 후 다시 poll 메소드를 호출한다.
auto commit 이랑 poll 이랑 무슨 상관이 있는것일까?
auto commit 의 동작원리
auto commit 의 동작원리는 commit request 를 만드는 CommitRequestManager 를 보면 알 수 있다.
CommitRequestManager 의 maybeAutoCommitAsync 메소드를 보면 internal 기간이 지났고 poll() 이 호출될 때 요청을 전송한다고 되어있다.
즉, poll() 메소드가 호출되어야 offset commit 요청이 전송되는것이다.

poll 메소드가 호출되면 무슨일이 일어나는지 조금 더 자세하게 알아보도록 하자.

위의 이미지는 poll 메소드의 코드이다.
중간즈음을 보면 pollForFetches(timer) 라는 코드가 있다. 이 코드가 실제 데이터를 가져오는 부분이라고 유추가 된다.
이 메소드를 조금 더 파해쳐보도록 하겠다.

poolForFetches 메소드 안에 들어가보면 위쪽에 collectFetch 라는 메소드를 호출하는것을 확인할 수 있다.
이 메소드를 통해 데이터를 가져오는것으로 보인다.
다시 한뎁스 더 들어가보도록 하자.

collectFetch 메소드 내부로 들어오면 데이터를 반환하기전에 ConsumerNetworkThread 를 wakeup 한다는 주석이 달려있다.
ConsumerNetworkThread 가 무슨일을 하는지 알아보도록 하자
ConsumerNetworkThread 의 runOne() 메소드를 보면 아래와 같은 주석이 달려있다.
KafkaClient.poll 메소드를 통하여 request 를 전송한다고 한다.

runOnce 메소드 내부를 살펴보면 requestManager 들의 poll 메소드를 호출하는것으로 보여진다.
auto commit 의 동작원리를 설명하는 처음부분에서 CommitRequestManager 의 maybeAutoCommitAsync 메소드에서 전송한다고 하였다.
CommitRequestManager 는 RequestManager interface 의 구현체이고 CommitRequestManager 의 poll 메소드안에서 maybeAutoCommitAsync 메소드를 호출하는것을 확인할 수 있다.

이로써 우리는 kafka 의 auto commit 이 어떠한 방식으로 이루어지는지 알아보았다.
댓글